RisingWave 是什么?
RisingWave 是一个分布式架构的 SQL 流式数据库,能简单、高效、可靠地处理流数据。
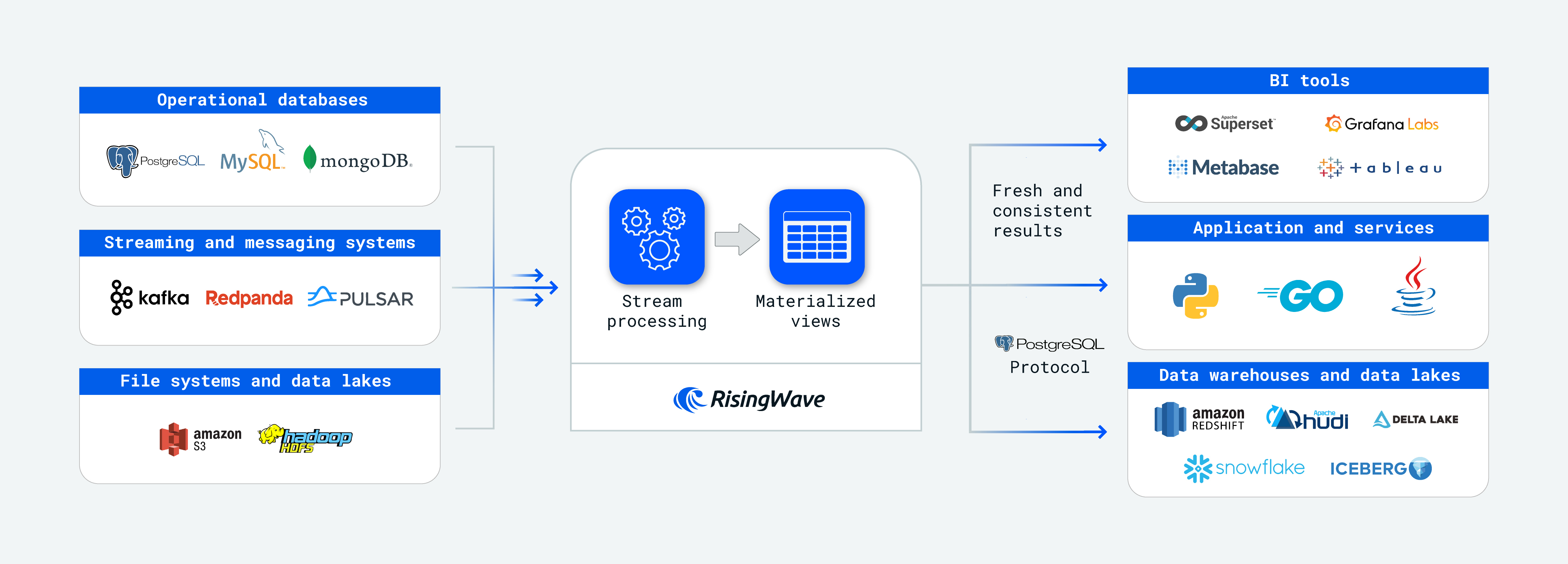
为什么选择 RisingWave 进行流处理?
RisingWave 提供增量更新、一致性的物化视图——这是一种持久的数据结构,承载了流处理的结果。RisingWave 让开发人员能够通过级联物化视图来表达复杂的流处理逻辑,从而大大降低了构建流处理应用的难度。此外,它还允许用户直接在系统内持久化数据,而无需将结果传送到外部数据库进行存储和查询。
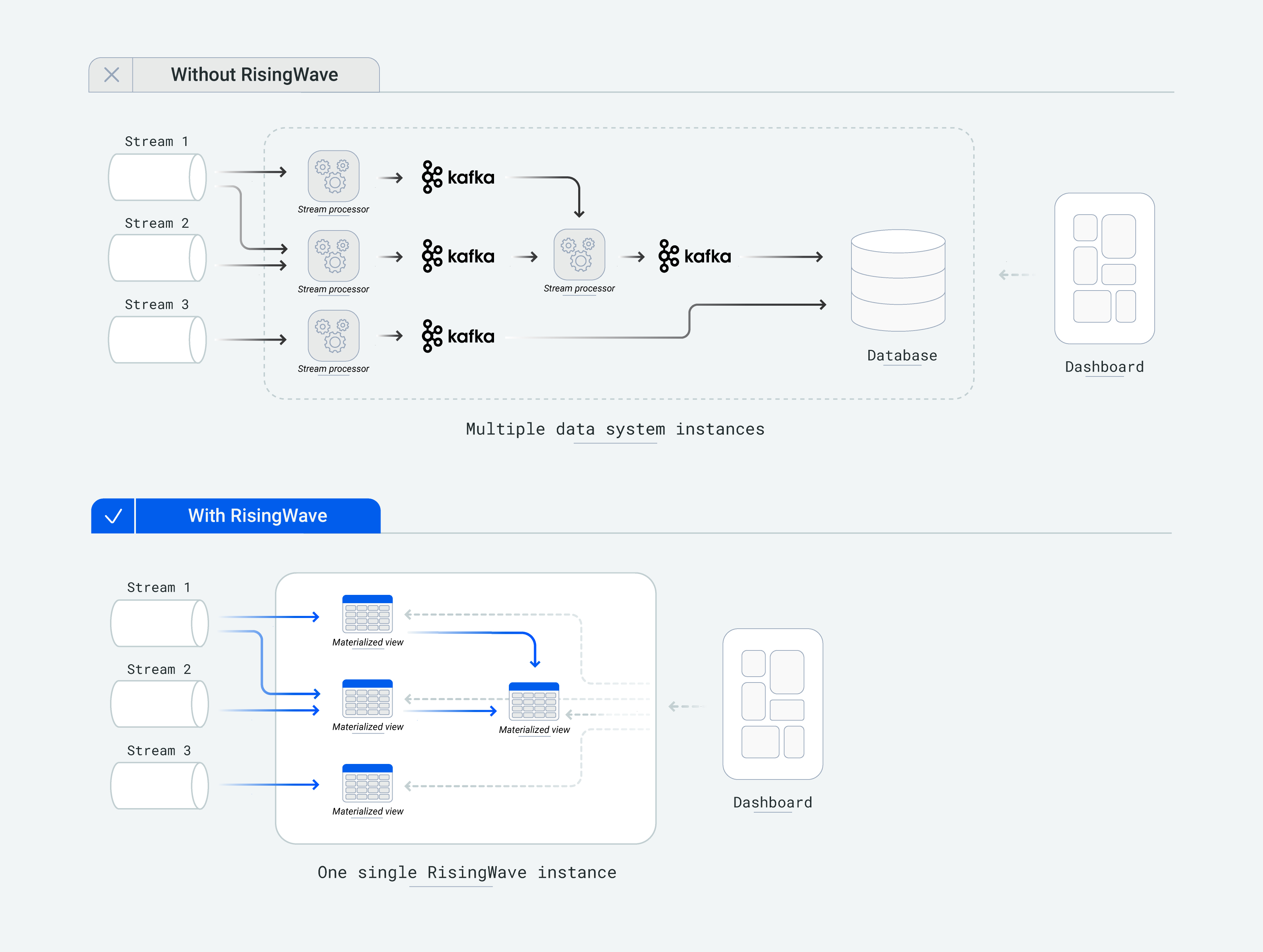
与 Apache Flink、Apache Spark Streaming 和 ksqlDB 等现有流处理系统相比,RisingWave 在两个主要方面脱颖而出:易用性和成本效益。这得益于它 PostgreSQL 式的交互体验和 Snowflake 式的架构设计(即存储和计算解耦)。
易用性
易于学习
RisingWave 采用 PostgreSQL 风格的 SQL 作为交互语言,使用户能够以使用 PostgreSQL 数据库的方式深入了解流处理。
易于开发
RisingWave 是一个关系型数据库,允许用户将流处理逻辑分解为更小型、可管理、堆叠的物化视图,从而无需面对复杂的计算程序。
易于集成
RisingWave 集成了各种云系统和 PostgreSQL 生态,拥有丰富而广泛的生态系统,可直接集成到您现有数据基础设施中。
成本效益
高效率复杂查询
RisingWave 将内部状态持久化在 S3 等远程存储中,用户可以在生产环境中放心、高效地执行复杂的流式查询(例如连接数十个数据流),而无需担心状态大小。
透明动态扩展
RisingWave 的状态管理机制可实现近乎瞬时的动态扩展,而不会中断服务。
即时故障恢复
RisingWave 的状态管理机制还能在数秒内从故障中恢复,无需等待几分钟甚至几小时。
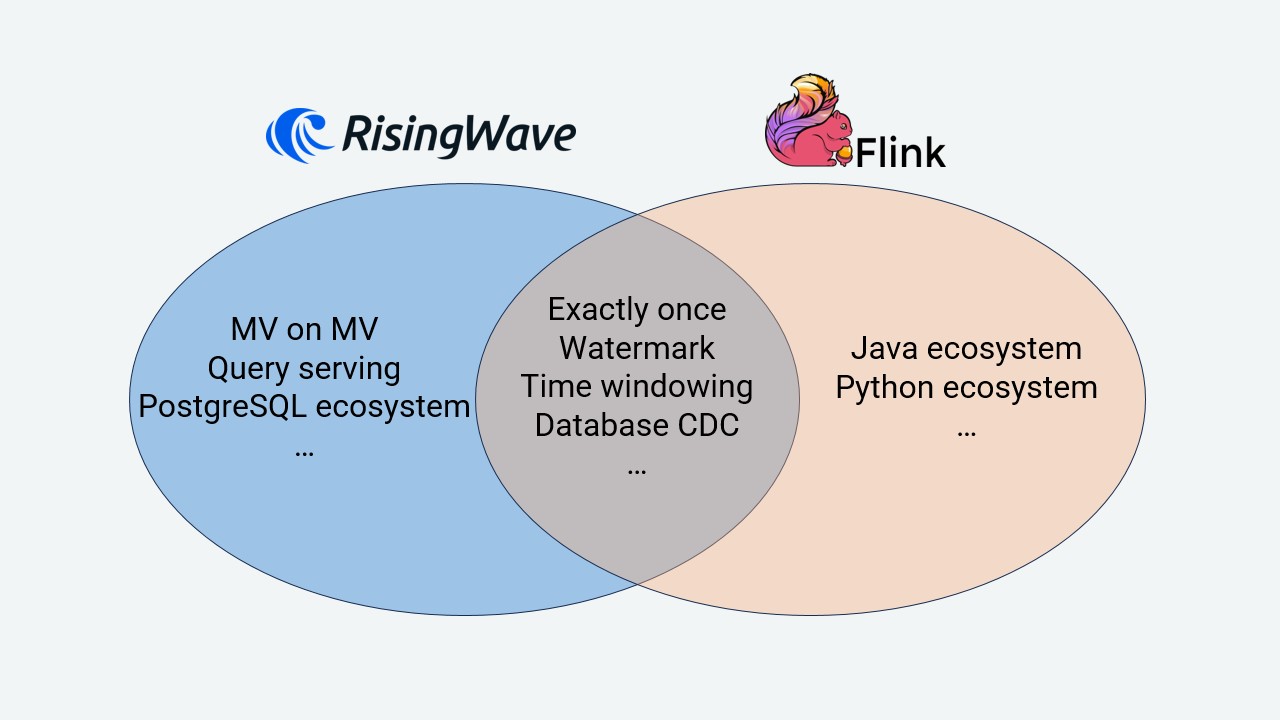
主要功能差异:RisingWave 对比 Flink
下图简单概括了 RisingWave 和 Flink 的主要功能差异。有关其差异的更多详细信息,请参阅 RisingWave vs. Apache Flink:如何进行选择?。
RisingWave 的局限性
RisingWave 并不能解决所有数据工程障碍,它有自己的局限性:
没有可编程接口
RisingWave 不提供 Java 和 Scala 等语言的底层应用接口,用户也无法手动管理内部状态(除非你想黑进去!)。如需使用 Java、Scala 和其他语言编码,请考虑使用 RisingWave 的用户定义函数(UDF)。
不支持事务处理
RisingWave 不支持事务型工作负载,因此无法替代专用于事务处理的操作型数据库。不过,它支持只读事务,可确保数据的新鲜度和一致性。它还能理解上游数据库变更数据捕获(CDC)的事务语义。
生产中的使用案例
和其他流处理系统一样,RisingWave 的主要用例包括监控、警报、实时看板报告、流式 ETL(提取、转换、加载)、机器学习特征工程等。已在金融交易、制造、新媒体、物流、游戏等领域得到应用。请参阅 使用案例。

