性能相关的主要指标
本文列举了 RisingWave Grafana 看板上显示的一些重要指标,了解这些指标有助于诊断潜在问题。
有关看板的详细信息,请查阅此文件。需要特别注意的是以下两个看板:
CPU 使用率
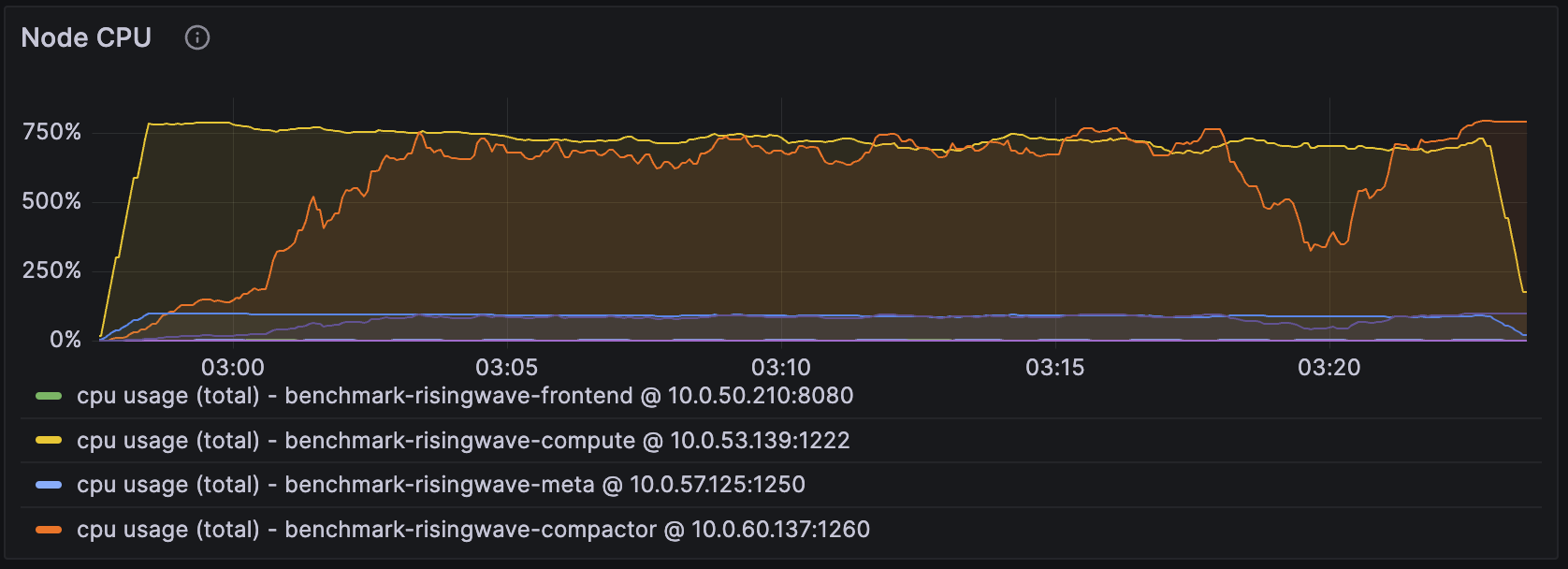
在所有组件中,我们主要关注 compute 节点和 Compactor 节点的 CPU 使用率。在上图的设置中,我们为 compute 节点分配了 8 个 CPU,为 Compactor 节点分配了 8 个 CPU。
关键点
当 compute 节点的 CPU 使用率接近该 compute 节点拥有的总 CPU 数量时(在本例中为 800%),我们可以通过为 compute 节点添加更多 CPU 来提高性能,例如吞吐量。
对 Compactor 节点可以采取相同的策略,下文介绍到“LSM 树压缩待处理字节”(该指标表明为压缩工作负载保留的理想 CPU 数量)时会重新回顾这一点。
内存使用率
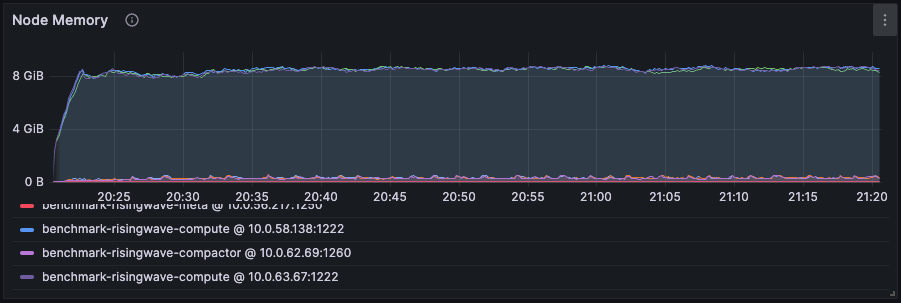
RisingWave 的内存控制机制大致如下:
RisingWave 计算和监控每个组件的内存使用情况。
RisingWave 保留总内存的 20% (即保留内存)作为缓冲。在输入数据突然增加时,RisingWave 有足够的时间调整其内存使用情况。
RisingWave 定期检查当前内存使用情况与总内存的其余 80%(即可用内存)之间的关系,并决定是否释放数据。如果超过可用内存的 70%,它会进行适当的处理。如果超过 80% 和 90%,则会采取进一步的措施。
在上图中,我们为 compute 节点分配了 12 GB 的内存,实际内存使用量在 8.64 GB(可用内存的 90%)左右波动,这表明 RisingWave 在尝试使用更多内存时会不断进行调整。
关键点
如果内存保持在 6.72 GB 以下(可用内存的 70%),可以确定工作负载只需这么多内存。也就是说,数据释放机制不会启用,数据/状态会完全保存在内存中。因此,可以调整内存资源以节省成本。
如果内存高于可用内存的 70%,在可以接受额外成本的情况下,会考虑分配更多内存以加速。此外,建议在做出此决定时考虑下面的 Cache miss 比率。
Cache miss
诸如 Join 和 Aggregation 之类的运算符是有状态的。它们在运算符缓存中保留中间状态,以便进行增量计算。
例如,以下 Join 运算符的 Cache miss 比率指标显示了在 actor 级别的指标。每个运算符由多个 actor 并行化,其数量与 streaming_parallelism 相同,默认情况下为 compute 节点上的 CPU 数量。
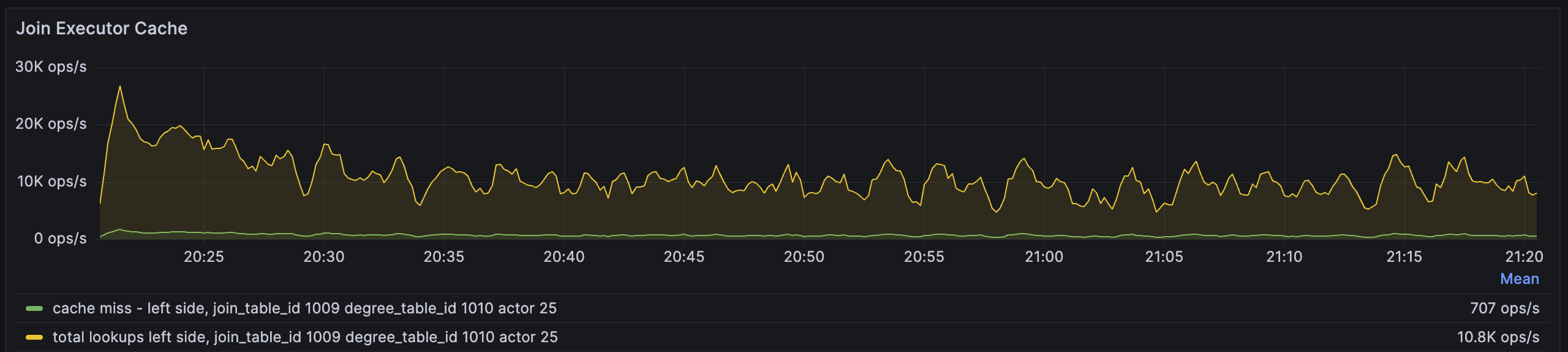
total lookups指标表示 Join 运算符每秒执行多少次查找,而 cache miss指标表示若键在内存中不存在,RisingWave 必须从存储引擎中获取的次数。
在上述情况中,Cache miss 比率为 707/10.8K~=6%,该数据相当低,增加内存可能不会产生太大效果。
以下是 Aggregation 运算符的 cache miss 比率指标。
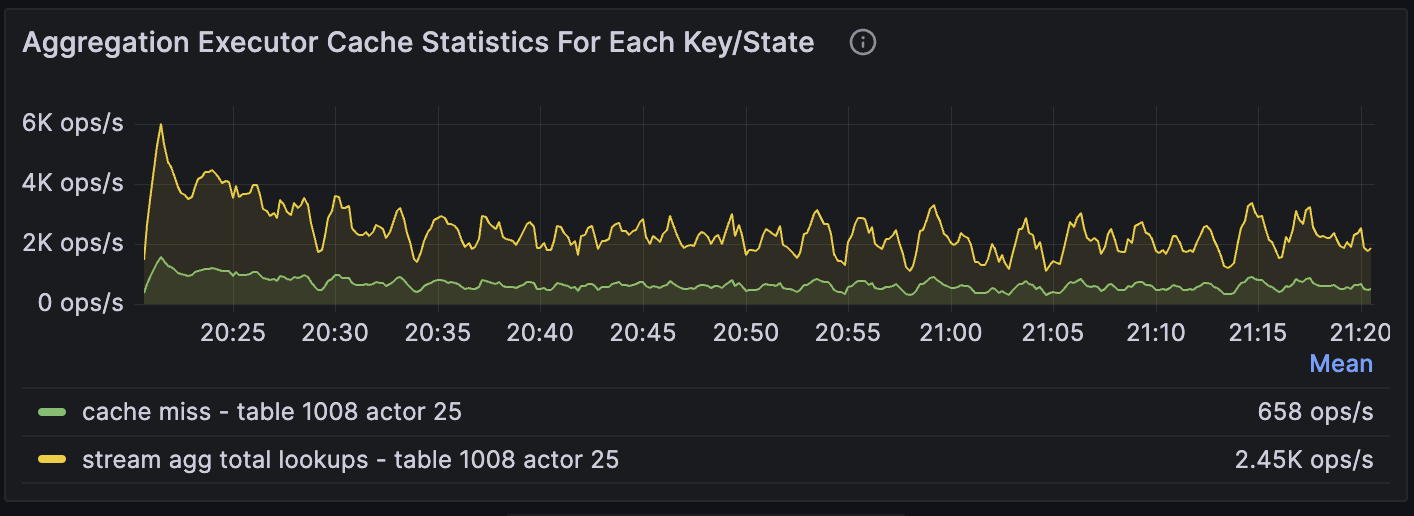
第 25 个 actor 的 Cache miss 比率为 658/2.45K ~= 27%,相对较高。这表明如果增加内存,性能可能会有所改善。
除了运算符缓存外,每个 compute 节点上的名为 Hummock 的存储引擎还维护块(数据)缓存和元数据缓存。数据缓存存储数据,与运算符缓存不同,块(数据)缓存以其二进制/序列化格式存储所有内容,所有运算符共享相同的块缓存,元数据缓存存储元数据。Hummock 需要元数据来定位它需要从 S3 读取的数据文件。
我们还可以观察以下两个缓存的 Cache miss 比率:
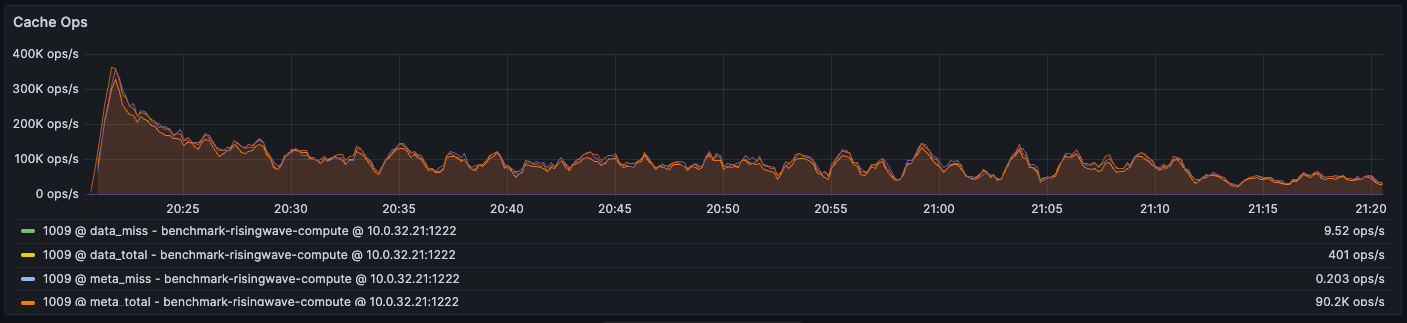
经计算,块(数据)缓存的 Cache miss 比率为 9.52/401 = 2%,元数据缓存的 Cache miss 比率为 0.203/90.2K ~= 0.0002%。
可以发现对元数据缓存的总查找次数远远高于对数据缓存的总查找次数,这是因为每次查找存储都需要经过元数据缓存,但并不一定每次都访问数据缓存或远程对象存储。元数据缓存具有布隆过滤器,以检查数据是否实际存在,从而减少远程提取次数。
这意味着即使在元数据缓存中只有小部分 Cache miss,由于总的未命中次数较多,也会引发显著的性能开销。
关键点
监视元数据缓存、块(数据)缓存和所有运算符缓存的 Cache miss 指标(按重要性排序),以估计潜在改进的空间。
Cache miss 的次数与比率一样重要,因为每次 Cache miss 都会产生与对象存储(如 S3)的远程 I/O 的延迟。
是否增加内存以提高性能取决于用户和工作负载:
- 用户能够承受多少额外成本
- 如果工作负载具有较弱的数据局部性,Cache miss 次数可能会少量减少,反之亦然。
LSM 树压缩待处理字节
如 CPU 使用率部分所述,我们可以通过考虑 LSM 树压缩待处理字节来估算为压缩器分配的理想 CPU 资源。
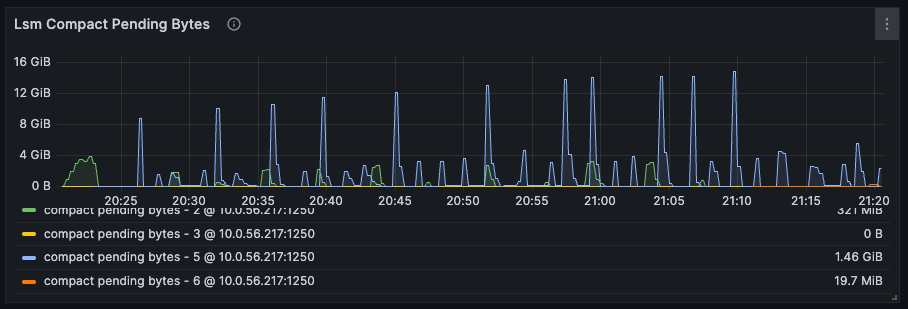
该指标从压缩器的角度显示了待处理工作负载的数量。由于压缩器的工作负载具有突发性质,只有当待处理字节在某个阈值以上保持了 10 分钟以后,才认为需要进行更改。
关键点
由于待处理字节的总量不断变化,我们首先计算其在超过 10 分钟的时间段内的平均值,再根据经验将平均值除以 4 GB 以估算理想 CPU 数量。
Barrier 延迟和 Barrier 数量
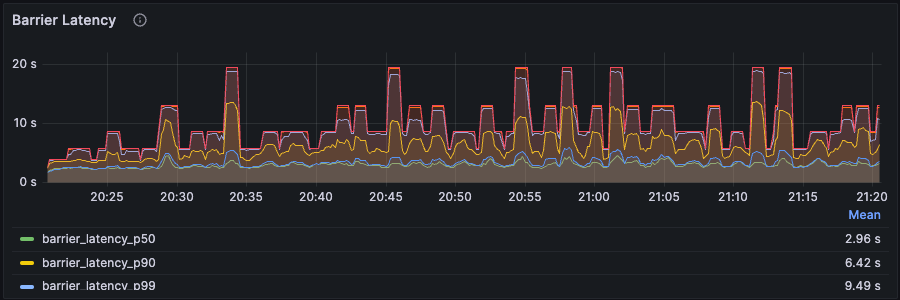
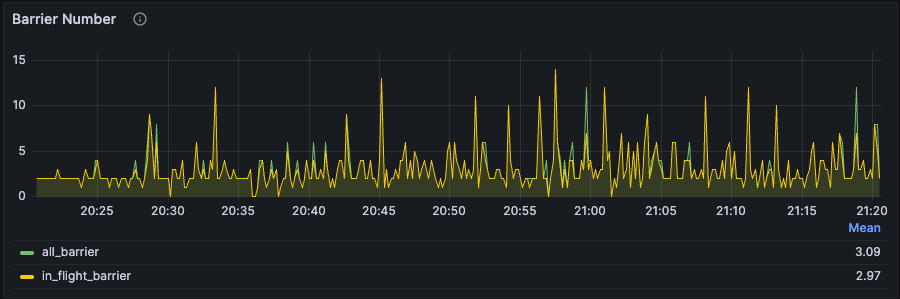
RisingWave 默认每秒生成一个 Barrier,并将其作为常规输入数据之一输入到 source 运算符(例如,从上游读取数据的运算符)中。当 Barrier 流经每个运算符时会有多种用途,例如触发当前 Barrier 和上一个 Barrier 之间的增量计算、将新状态刷新到存储引擎、确定检查点的完成等。
理想情况下,Barrier 延迟应保持在 1 秒钟。但实际操作中通常会有以下两种现象:
Barrier 延迟不断增加,从未进入稳定阶段。与此同时,Barrier 数量也不断增加。这意味着系统严重拥塞,即当前资源不足以处理工作负载。这需要通过检查上述其他指标来增加 CPU 或内存资源。
Barrier 延迟和 Barrier 数量波动,但仍在某个水平附近保持稳定,这属于正常现象。由于流数据的动态性和 RisingWave 的动态 back-pressure 机制,出现这些现象是正常的,因为 RisingWave 在任何给定的秒数内都在不断调整。
关键点
登录 Grafana 诊断任何性能问题或错误时,首先检查 Barrier 延迟和 Barrier 数量。若遇到第一种现象,需要进一步调查所需的资源。
Source 吞吐量
在无状态查询中(例如,仅转换数据而不涉及有状态计算的简单 ETL 查询中),容易发现 RisingWave 可能会受到其上游系统限制的瓶颈影响。
例如,RisingWave 可能从上游消息队列读取数据。如果消息队列的磁盘带宽或 RisingWave 与消息队列之间的网络带宽太低,source 吞吐量可能无法充分利用 RisingWave 的资源。
关键点
建议用户监视 RisingWave 上游系统(例如消息队列或数据库)的 CPU 利用率、磁盘 I/O 和网络 I/O,以确定端到端的瓶颈。
有关性能优化的任何其他问题,请关注我们的 RisingWave 中文开源社区公众号并加入社群,或加入 Slack 英文社区,与广大用户群体一同参与讨论、寻求帮助、分享经验,我们的工程师将提供相应的解决方案。

