从 RisingWave 导出数据到 PostgreSQL
本文将向您展示如何使用 JDBC 连接器从 RisingWave 导出数据到 PostgreSQL。Sink 参数与其他支持 JDBC 的数据库(如 MySQL)类似。然而,我们将专门介绍针对 PostgreSQL 的配置以及如何验证数据是否成功导出。
您可以通过使用 RisingWave 仓库中 integration_test 目录 的 postgres-sink 演示,在您自己的设备上测试此过程。
设置 PostgreSQL 数据库
- AWS RDS
- 自托管
在 AWS 上设置 PostgreSQL RDS 实例
这里我们将使用标准类实例、非多可用区部署作为示例。
登录 AWS 控制台。在服务中搜索 “RDS” 并选择 RDS 面板。
使用 PostgreSQL 作为 引擎(Engine) 类型创建数据库。我们建议设置用户名和密码或使用其他安全选项。
当新实例可用时,点击其面板。
从连接性面板,我们可以找到端点和连接端口信息。
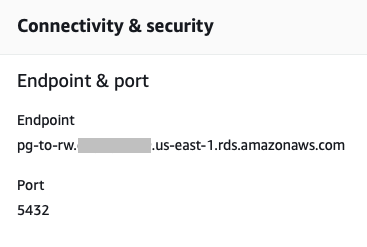
从 Postgres 连接到 RDS 实例
现在我们可以连接 RDS 实例了。确保您的本地机器上安装了 psql,并打开了 psql Prompt。在连接参数中填写端点、端口和登录凭证。
psql --host = pg-to-rw.xxxxxx.us-east-1.rds.amazonaws.com --port=5432 --username=awsuser --password
更多登录选项,请参考 RDS 连接指南。
在 PostgreSQL 中创建表
使用以下查询在 PostgreSQL 中设置表。我们将从 RisingWave 导出数据到这个表。
CREATE TABLE target_count (
target_id VARCHAR(128) PRIMARY KEY,
target_count BIGINT
);
设置 RisingWave
安装并启动 RisingWave
要在本地安装并启动 RisingWave,请参见 快速上手指南。我们推荐本地运行 RisingWave 以进行测试。
从二进制文件运行 RisingWave 的注意事项
如果您正在本地从二进制文件运行 RisingWave,并打算使用原生 CDC Source 连接器或 JDBC Sink 连接器,请确保您的环境中安装了 JDK 11 或更高版本。
创建 Sink
句法
CREATE SINK [ IF NOT EXISTS ] sink_name
[FROM sink_from | AS select_query]
WITH (
connector='jdbc',
field_name = 'field', ...
);
参数
除非特别注明,否则所有 WITH 选项都是必填的。
| 参数或子句 | 描述 |
|---|---|
| sink_name | 要创建的 Sink 名称。 |
| sink_from | 指定将从中输出数据的直接来源子句。sink_from 可以是物化视图或表。必须指定此子句或 SELECT 查询。 |
| AS select_query | 指定要输出到 Sink 的数据的 SELECT 查询。必须指定此查询或 FROM 子句。参见 SELECT 以了解 SELECT 命令的句法和示例。 |
| connector | Sink 连接器类型必须为 'jdbc' 以适用于 PostgreSQL Sink。 |
| jdbc.url | 目标数据库的 JDBC URL,对于驱动程序识别并连接到数据库是必需的。 |
| table.name | 您想要导出到的目标数据库中的表。 |
| schema.name | 可选。您想要导出到的目标数据库中的 Schema。默认值是 public。 |
| type | Sink 数据类型。支持的类型:
|
| primary_key | 如果 type 是 upsert,则为必填项。Sink 的主键,应与下游表的主键相匹配。 |
从 RisingWave 导出数据到 PostgreSQL
创建 Source 和物化视图
您可以从 RisingWave 中的表、Source 或物化视图导出数据到 PostgreSQL。
出于演示目的,我们将创建一个 Source 和一个物化视图,然后从物化视图导出数据。如果您已经有了一个表或物化视图用于导出数据,那么您不需要执行此步骤。
运行以下查询从 Kafka Broker 读取数据创建 Source。
CREATE SOURCE user_behaviors (
user_id VARCHAR,
target_id VARCHAR,
target_type VARCHAR,
event_timestamp TIMESTAMPTZ,
behavior_type VARCHAR,
parent_target_type VARCHAR,
parent_target_id VARCHAR
) WITH (
connector = 'kafka',
topic = 'user_behaviors',
properties.bootstrap.server = 'message_queue:29092',
scan.startup.mode = 'earliest'
) FORMAT PLAIN ENCODE JSON;
接下来,我们将创建一个物化视图,查询每个 target_id 的目标数量。注意物化视图和目标表有相同的 Schema。
CREATE MATERIALIZED VIEW target_count AS
SELECT
target_id,
COUNT(*) AS target_count
FROM
user_behaviors
GROUP BY
target_id;
从 RisingWave 导出数据
使用以下查询将数据从物化视图导出到 PostgreSQL 中的目标表。确保 jdbc_url 是准确的,并且反映了您正在连接的 PostgreSQL 数据库。详见 CREATE SINK 以获取更多详情。
CREATE SINK target_count_postgres_sink FROM target_count WITH (
connector = 'jdbc',
jdbc.url = 'jdbc:postgresql://postgres:5432/mydb?user=myuser&password=123456',
table.name = 'target_count',
type = 'upsert',
primary_key = 'target_id'
);
验证更新
为确保目标表已更新,请从 PostgreSQL 中的 target_count 查询。
SELECT * FROM target_count
LIMIT 10;
数据类型映射
有关 PostgreSQL 数据类型映射表,请参见在 从 PostgreSQL CDC 导入数据 - 数据类型映射表。
关于导出数据到 PostgreSQL 的附加说明:
RisingWave 中的
varchar列可以导出到 PostgreSQL 中的uuid列。只有 RisingWave 中的一维数组可以导出到 PostgreSQL。

