OOM 故障排除
内存溢出(OOM)是数据处理系统中常见的问题,可能有多种原因。本文将分析 OOM 的根本原因并有效解决这些问题。
RisingWave 使用像 AWS S3 这样的共享存储,并将 Compute 节点的内存用作缓存以增强流处理性能。缓存以 Least Recently Used (近期最少使用算法,LRU) 的方式运作,即当内存不足时,将删除最少使用的条目。
为了获得最佳性能,建议 Compute 节点的最低内存为 8 GB,但生产环境中建议使用 16 GB 及以上。
本文重点解决 Compute 节点上的 OOM 问题。如果在其他节点上遇到 OOM,请首先升级到最新版本。如果问题仍然存在,请联系我们。
OOM 症状
- Kubernetes 显示 Compute 节点 Pod 由于 OOM Killed (137) 而突然重新启动。
- Grafana 指标显示内存无限增长,超出了为 Compute 节点设置的
total_memory限制。内存设置可以在 Compute 节点的启动日志中找到。搜索关键字“Memory outline"以定位特定部分。
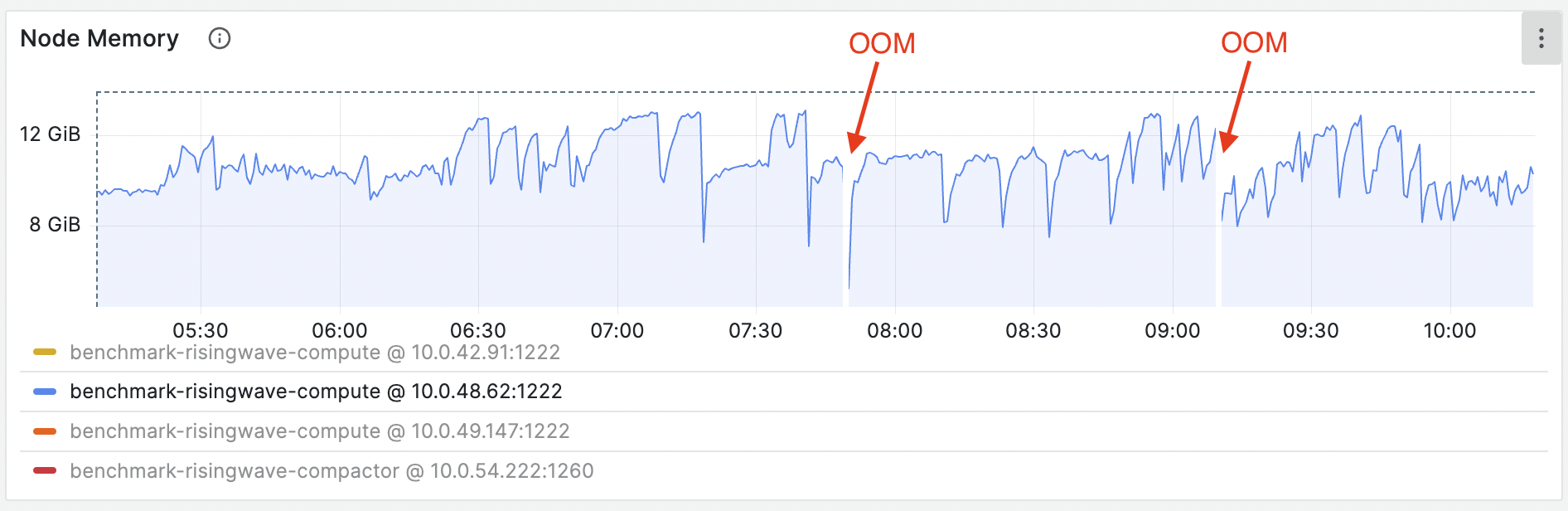
创建物化视图时的 OOM
如果在创建新的物化视图时发生 OOM,可能是由上游系统(如 Kafka)中存在的大量现有数据引起的。这种情况下,在创建或重新创建物化视图之前,可以通过指定每个并行度的速率限制来减少流量:
CREATE MATERIALIZED VIEW mv WITH ( streaming_rate_limit = 200 ) AS ...
参数streaming_rate_limit表示每个并行度在每个源上的每秒最大记录数,其中流作业的默认并行度是集群中所有 CPU 核心的总数。例如,假设一个物化视图有 4 个并行度和 2 个 Source 连接在一起,每个 Source 的吞吐量将被限制为4 * streaming_rate_limit条记录/秒。
或者,您可以使用risectl来更改现有物化视图的流速限制,其中<id>可以在 RisingWave 看板或 rw_catalog Schema 中找到。
risingwave ctl throttle source/mv <id> <streaming_rate_limit>
屏障延迟导致的 OOM
屏障在我们的系统中发挥着关键作用,支持内存管理和 LRU 缓存等重要组件的正常运行。
从 Grafana 看板的屏障延迟面板可以观察到屏障延迟,如图所示,延迟曲线异常。
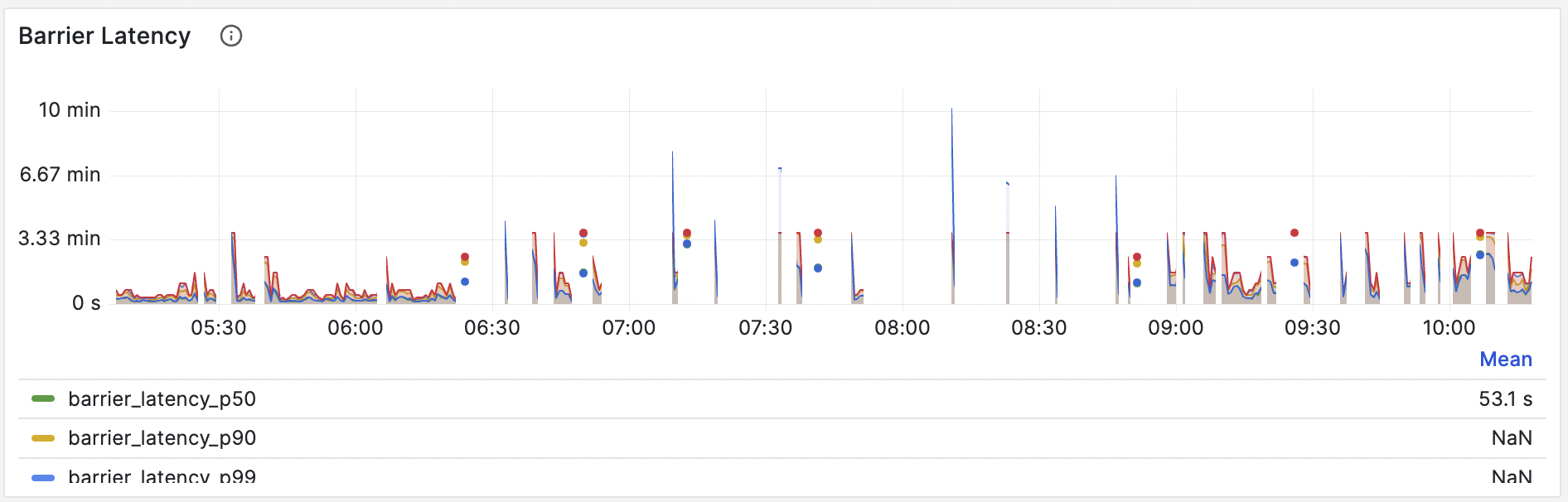
与仅解决内存问题不同,建议关注为何屏障出现问题。可能是由繁重的流作业、输入流量的突然冲击或一些临时问题引起。
以下方法可以帮助解决此问题:
- 在 Grafana 中,观察片段(actor)之间的背压。两个片段之间的高背压表明下游片段无法足够快地处理数据,从而减慢整个流作业的速度。
- 在 RisingWave 看板中检查所有 Compute 节点的 Await Tree Dump。如果屏障陷入困境,Await Tree Dump 将显示屏障正在等待特定操作完成。这个片段可能是流作业的瓶颈。
不管是哪种情况,您都可以试着将更多节点添加到集群中,以增加并行度,或检查 SQL 查询语句看看是否有优化的空间。
长时间批量查询时的 OOM
如果在长时间批查询期间发生 OOM,可能是由 Compute 节点上的内存使用过多而引起。在这种情况下,可以通过调整 TOML 文件中的storage.prefetch_buffer_capacity_mb 参数来减少预取的内存使用。
storage.prefetch_buffer_capacity_mb 参数定义了预取的最大内存。它通过预读来优化流执行器和批查询性能。此功能允许 hummock 在单个 I/O 操作中读取更大的数据块,但这样一来,内存成本更高。当预取操作期间的内存使用达到此限制时,hummock 将恢复到原始读取方法,以 64 KB 块处理数据。如果将参数设置为 0,则将禁用此功能。默认情况下,它设置为总机器内存的 7%。
使用内存分析工具进行故障排除
如果屏障延迟正常,但内存使用仍在增加,可能需要进行内存分析以找出根本原因。
我们在 RisingWave 看板中添加了堆分析工具,以帮助您分析内存使用情况并识别与内存相关的问题。
要启用内存分析,请为 Compute 节点设置环境变量MALLOC_CONF=prof:true。
进入 RisingWave 看板,选择 Debug > Heap Profiling。如果您正在本地机器上运行 RisingWave,可以通过 127.0.0.1:5691 访问 RisingWave 看板。
默认情况下,当内存使用达到 90% 时,heap profile 数据将自动转储,也可以选择手动转储。转储数据后,在看板内单击 Analyze,以检查内存使用模式和潜在问题,而无需离开看板界面。
在社群寻求帮助
您可以加入我们的 Slack 工作区 并在 #troubleshooting 频道中发布您的问题以寻求社群帮助,或 在 GitHub 中提交问题。您也可以关注 RisingWave 中文开源社区公众号并加入社群,与广大用户群体一同参与讨论、寻求帮助、分享经验。
在提交问题时,请包括以下详细信息:
问题摘要。 重现问题的步骤。 相关资源,如日志、截图、指标、堆栈转储等。

