故障排除
本文假定您使用 RisingWave K8s Operator 在 K8s 上部署 RisingWave。在 Operator 中,我们打包了 RisingWave、RisingWave 看板以及诸如 Prometheus 和 Grafana 之类的第三方可观测性和日志工具。
监控您的集群
获取集群概览
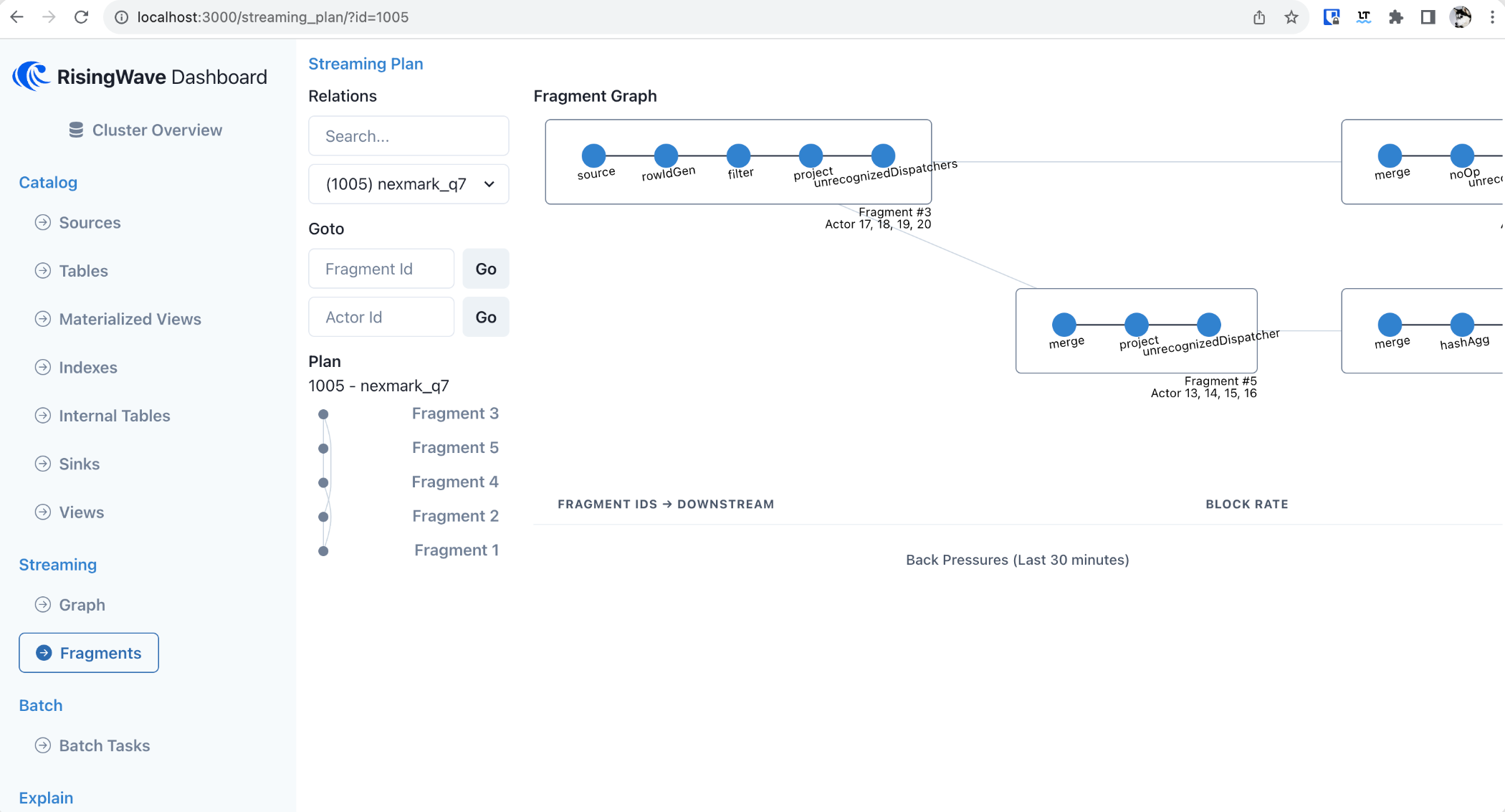
RisingWave 看板为 RisingWave 的内建看板。通过它,您可以获取有关 RisingWave 集群的概览,包括您创建的对象、流处理或批处理任务的执行详情。可以查看的对象包括数据源、表格、物化视图、索引、内部表和数据下游。
您可以通过默认地址 http://localhost:5692 访问 RisingWave 看板。
查看性能指标
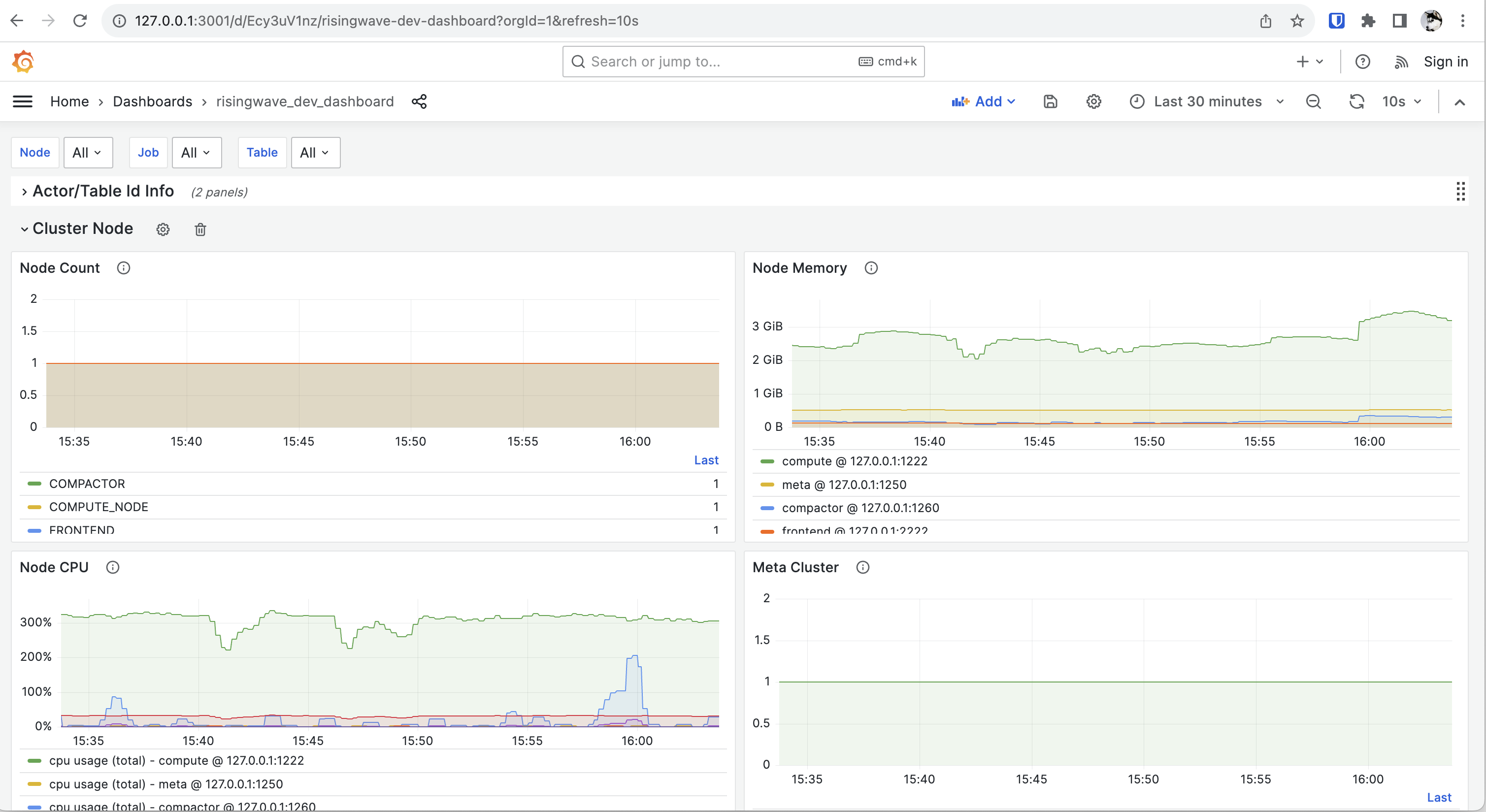
您可以监视 RisingWave 集群的性能指标,包括资源使用情况(如 CPU、内存和网络)以及不同节点的状态。
RisingWave 使用 Prometheus 收集数据,并使用 Grafana 进行可视化和警报。这个监控堆栈需要进行配置。有关配置监控堆栈的步骤,请参阅 监控 RisingWave 集群。
完成配置后,访问 http://localhost:3000 以从本地计算机访问 Grafana,或访问 [http://<client_address>:3000] 以从不同主机访问 Grafana,其中 <client_address> 是运行 Grafana 服务的机器的 IP 地址。在提示时,输入默认凭据(用户名:admin;密码:prom-operator)。
官方版本中包含了两个内建看板。
- risingwave_dashboard 包含面向用户的关键指标。
- risingwave_dev_dashboard 包含更多面向 RisingWave 开发者的低级别指标。
查看错误消息和日志
通常,出现问题时会收到错误消息,并提供有关问题的基本信息。我们正在总结常见的错误和解决方案,并筹备发布。
RisingWave 的日志默认输出到 stdout。如果您通过我们的官方 Kubernetes Operator 部署 RisingWave,可以使用 kubectl logs 命令查看它们。
建议您部署专用的日志系统,例如 Grafana Loki 或 Elasticsearch。
利用系统目录
系统目录提供有关 RisingWave 中对象的定义和元数据的全面信息。有关可用系统目录的详细列表,请参阅 系统目录。
支持资源
获取帮助的最直接方式是在我们的 Slack 社区工作区 中报告您的问题。
在 Slack 工作区中报告问题时,请记得上传日志,这有助于我们的工程师进行故障排除。
您也可以关注 RisingWave 中文开源社区公众号并加入社群,与广大用户群体一同参与讨论、寻求帮助、分享经验。
提交问题
如果您尝试自行解决问题但未成功,可以在 GitHub 中提交问题。
请在 GitHub 问题中包含以下详细信息:
- 问题摘要。
- 重现问题的步骤。
- 预期的结果。
- 实际发生的结果。

